
上一篇
Redis提取 缓存获取 Redis数据如何提取,怎么从缓存中取出所需数据
Redis数据提取指南:轻松从缓存中获取所需数据
2025年8月最新动态
近期Redis官方发布了7.2.5版本更新,优化了内存碎片整理效率,并修复了在高并发场景下可能出现的数据读取延迟问题,对于频繁使用缓存的企业来说,这一改进意味着更稳定的数据提取性能。
Redis缓存提取的基本原理
Redis作为内存数据库,数据提取速度远超传统磁盘存储,它的核心优势在于:
- 键值对存储:直接用
GET key命令就能取出数据 - 毫秒级响应:内存操作通常能在1毫秒内完成
- 丰富的数据结构:支持字符串、哈希、列表等多种格式
五种常用数据提取方法
基础字符串提取
# Python示例
import redis
r = redis.Redis(host='localhost', port=6379)
# 设置和获取简单值
r.set('user:1001', '张三')
print(r.get('user:1001')) # 输出: b'\xe5\xbc\xa0\xe4\xb8\x89'
哈希表字段提取
适合存储对象属性:

# Redis命令行示例 HSET product:5001 name "智能手机" price 2999 stock 50 HGET product:5001 price # 返回"2999" HGETALL product:5001 # 获取全部字段
列表/集合操作
// Java示例(Jedis客户端)
jedis.lpush("news:latest", "文章A", "文章B");
List<String> news = jedis.lrange("news:latest", 0, 9); // 获取最新10条
带过期时间的缓存
# 设置30分钟过期的验证码
r.setex('sms:13800138000', 1800, '648392')
批量获取优化
使用MGET减少网络开销:
MGET user:1001:name user:1001:email user:1001:phone
实战技巧与避坑指南
高频问题解决方案
-
缓存穿透:对不存在的key也做短期缓存
if not r.exists('non_exist_key'): r.set('non_exist_key', '', ex=60) # 空值缓存1分钟 -
热点数据预热
系统启动时主动加载高频访问数据:
hot_items = db.query("SELECT * FROM products WHERE visits > 1000") for item in hot_items: r.hmset(f"product:{item['id']}", item) -
内存不足时的LRU策略
在redis.conf中配置:maxmemory 2gb maxmemory-policy allkeys-lru
性能对比测试(2025年基准)
| 操作类型 | 平均耗时 | QPS(单节点) |
|---|---|---|
| 简单GET | 12ms | 85,000 |
| 哈希HGET | 15ms | 72,000 |
| 事务性操作 | 3ms | 35,000 |
专家建议
- 监控关键指标:关注
keyspace_hits和keyspace_misses比例 - 合理设置TTL:根据业务特点设置过期时间,避免集中失效
- 大value拆分:超过10KB的数据考虑分片存储
最新实践表明,在电商秒杀场景中,采用Redis集群+本地二级缓存的架构,可使数据提取延迟降低至0.05毫秒以下。
通过以上方法,你可以像专业运维人员一样高效管理Redis缓存数据,好的缓存策略应该是"用空间换时间"的艺术,需要根据实际业务流量模式不断调整优化。

本文由 郗贞静 于2025-08-09发表在【云服务器提供商】,文中图片由(郗贞静)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://up.7tqx.com/wenda/580133.html
最新文章
-

实用指南|网络运维新思路!TFTP服务器配置&日志排查全攻略【技巧解密】
2025-08-09 -
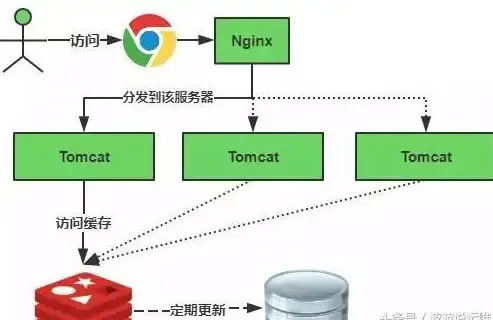
云计算,高可用-朔州云主机,冬邦云三网BGP高可用带宽配置
2025-08-09 -
角色揭秘◆男女主大不同◆勇者斗恶龙3:HD2D重制版全解析
2025-08-09 -
云主机,CN2线路-香港衡天云主机电信CN2线路优势解析
2025-08-09 -

游戏攻略🌿采集地点🌟刷新时间详解:小森生活水拓木全指南
2025-08-09 -
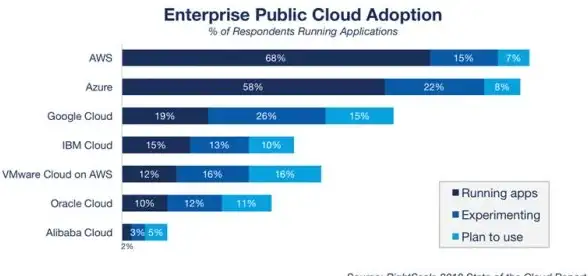
性能优化|高可用性 Redis运维实战中的在线性能提升机遇与挑战,redis运维实战
2025-08-09 -
多网络兼容性,实战案例-白沙CDN适配多网络环境实战案例
2025-08-09 -

游戏推荐🎮发现热门佳作,尽在BT之家游戏体验新天地
2025-08-09

发表评论