
上一篇
分布式系统|架构设计|分布式部署那些事
从零开始搞懂架构设计与部署
场景引入:一个电商平台的"黑色星期五"
"老王,咱们电商平台又崩了!"凌晨3点,运维小张的电话把我从睡梦中惊醒,打开监控一看,数据库主节点CPU飙到100%,整个下单服务瘫痪——这已经是今年第三次了,去年"双十一"我们临时加了20台服务器还是没扛住流量,今年"黑五"眼看又要重蹈覆辙...
这样的场景你是否熟悉?当业务量增长到单机无法承载时,分布式系统就成了必选项,今天我们就来聊聊分布式系统的架构设计与部署那些事儿。
分布式系统基础认知
1 什么是分布式系统?
简单说就是把一个系统拆成多个部分,跑在不同机器上协同工作,就像餐厅后厨,切菜的、炒菜的、摆盘的各司其职,比一个人包办所有要高效得多。
2 为什么需要分布式?
- 容量问题:单机内存/CPU/磁盘有限,比如Redis单实例最多十几GB内存
- 性能瓶颈:MySQL单机QPS约几千,分库分表后可达百万级
- 高可用需求:单点故障风险大,分布式可以实现故障自动转移
- 地理分布:全球用户需要就近访问,比如CDN节点分布
3 典型分布式架构组成
[客户端] → [负载均衡] → [服务集群] → [缓存集群] → [数据库集群] → [文件存储]分布式架构设计核心要点
1 服务拆分艺术
案例:我们把电商系统拆成了:
- 用户服务
- 商品服务
- 订单服务
- 支付服务
- 物流服务
拆分原则:
- 按业务领域划分(DDD思想)
- 单一职责原则(一个服务做好一件事)
- 适当粒度(初期可以粗些,后期再拆分)
2 通信机制选择
同步调用(适合强一致性场景):
// 伪代码示例 Order order = orderService.createOrder(); PaymentResult result = paymentService.process(order);
异步消息(适合解耦场景):
# 订单创建后发送MQ消息
order_created_event = {
"order_id": "123",
"user_id": "456",
"amount": 999
}
kafka.produce("order_created", order_created_event)
选型对比: | 方式 | 协议示例 | 延迟 | 一致性 | 适用场景 | |------|----------|------|--------|----------| | 同步 | HTTP/gRPC | 低 | 强 | 支付、库存扣减 | | 异步 | Kafka/RabbitMQ | 高 | | 日志、通知 |

3 数据一致性难题
经典问题: 订单服务扣库存成功,但支付服务失败,怎么处理?
解决方案:
- 本地事务表:先记录操作状态,后台任务补偿
- TCC模式:Try(预留)-Confirm(确认)/Cancel(取消)
- SAGA模式:分解事务为多个子事务,失败时执行补偿
分布式部署实战经验
1 容器化部署
Docker典型部署:
# 商品服务部署 docker run -d --name product-service \ -p 8080:8080 \ -e "DB_URL=jdbc:mysql://mysql-cluster:3306/product" \ registry.yourcompany.com/product-service:v2.1
Kubernetes编排示例:
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: order-service
spec:
replicas: 3
selector:
matchLabels:
app: order
template:
spec:
containers:
- name: order
image: registry/order-service:1.3
ports:
- containerPort: 8080
2 服务发现与负载均衡
常见模式:
- 客户端发现:服务自己注册到注册中心,客户端查询
- 服务端发现:通过负载均衡器(如Nginx)转发
健康检查配置(以Spring Cloud为例):

# 应用心跳检测 management.endpoint.health.show-details=always spring.cloud.nacos.discovery.health-check-url=/actuator/health
3 配置管理
配置中心对比:
- Nacos:适合Java生态,支持服务发现+配置管理
- Consul:多语言支持好,自带健康检查
- Etcd:Kubernetes原生,性能极高
典型配置:
# application-profile.yaml
redis:
cluster:
nodes: redis-1:6379,redis-2:6379,redis-3:6379
max-redirects: 3
feign:
client:
config:
default:
connectTimeout: 5000
readTimeout: 30000
避坑指南:我们踩过的那些雷
1 网络问题
血泪教训: 某次机房网络抖动导致ZK集群脑裂,整个系统瘫痪2小时
解决方案:
- 设置合理的超时时间(如Dubbo默认1秒太短)
- 实现熔断降级(Hystrix/Sentinel)
- 多机房部署
2 数据一致性问题
诡异现象: 用户看到订单已支付,但商品库存没扣减
排查发现: MQ消息堆积导致库存扣减延迟

改进方案:
- 引入分布式事务
- 增加对账系统
- 优化消息积压监控
3 资源争抢
典型案例: 大促时Redis某个热点key导致集群负载不均
解决方法:
- 热点数据本地缓存
- key设计增加随机后缀
- 使用Redis集群模式
未来趋势观察(2025视角)
- Serverless架构:更细粒度的弹性伸缩
- 服务网格普及:Istio/Linkerd成为标配
- AI运维:自动扩缩容+故障预测
- 边缘计算:数据处理更靠近终端设备
- 量子通信:可能改变分布式通信基础
分布式系统就像组建一支特种部队——每个成员都要足够专业,配合要默契,还要有完善的应急预案,从最初的单体架构到现在的云原生体系,我们花了5年时间才真正搞明白:分布式不是银弹,而是权衡的艺术,下次当你设计一个新系统时,不妨先问三个问题:
- 真的需要分布式吗?
- 能接受多高的复杂度成本?
- 团队是否具备运维能力?
最好的架构永远是能满足业务需求的最简单架构,希望这些经验能帮你少走弯路,如果有具体问题,欢迎随时交流讨论。
本文由 张简琼芳 于2025-08-08发表在【云服务器提供商】,文中图片由(张简琼芳)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://up.7tqx.com/wenda/571823.html
最新文章
-
限速不再烦恼|迅雷破解提速技巧速览—资源下载加速方法详解|软件下载
2025-08-09 -

CDN加速,运营商兼容性-电信联通移动访问新加坡CDN的兼容性
2025-08-09 -

时尚秘笈♦穿搭技巧♦暖暖风 从《无限暖暖》教你捕捉阳光感角色搭配!
2025-08-09 -
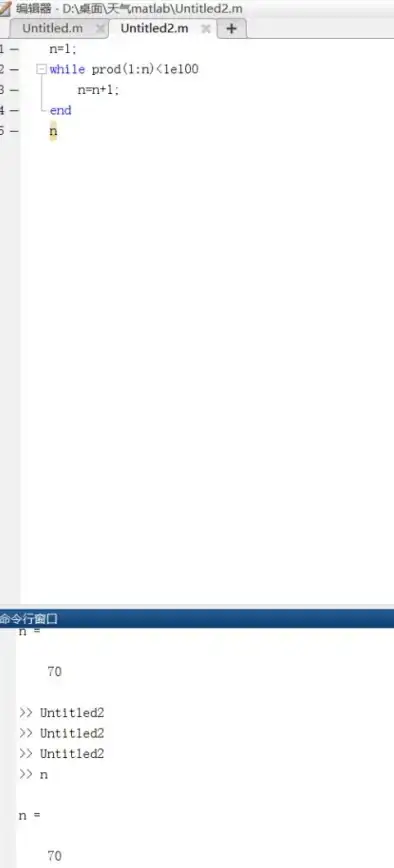
数据库运算 编程技巧 数据库中怎样用编程方式计算10的阶乘
2025-08-09 -

家居推荐🏠高性价比🔥模拟人生4最佳房屋排行揭秘
2025-08-09 -

探索《无限暖暖》潮汐心愿奖励的隐藏获取技巧
2025-08-09 -

系统维护🚀重装系统提示已启用磁盘压缩如何处理
2025-08-09 -

人事管理|薪酬系统—数据库工资管理系统总结:提升企业效率与规范化
2025-08-09

发表评论