
上一篇
Redis优化 数据提取 优化Redis配置提升数据获取速度,解决redis获取全部数据慢的问题
🔥 Redis提速秘籍:告别龟速数据提取的全套优化方案
📢 最新动态
根据2025年8月Redis官方社区报告,全球超过67%的开发者仍在使用未优化的默认配置!而经过调优的Redis实例数据提取速度平均提升8倍,你的Redis还在"散步模式"吗?
💡 为什么你的Redis比蜗牛还慢?
先别急着砸键盘!遇到keys *卡成PPT、批量获取数据等到花儿都谢了的情况,八成是这些原因在搞鬼:
- 配置躺平:默认配置就像没调校的跑车,根本发挥不出性能
- 暴力查询:无脑用
keys命令扫全库(⚠️ 生产环境禁用!) - 内存打架:没有合理设置淘汰策略,导致频繁内存回收
- 网络拖后腿:单线程遇上大体积数据,传输变"滴灌"
🚀 四步火箭式提速方案
第一步:给Redis穿上"跑鞋" 🏃
# redis.conf 核心参数调整 maxmemory 8gb # 设为可用物理内存的70% maxmemory-policy allkeys-lru # 内存不足时优先淘汰久未使用的key hz 10 # 提高后台任务频率(默认10,可调至50-100) tcp-keepalive 300 # 防止网络连接假死
💡 小贴士:用CONFIG REWRITE命令动态生效,无需重启服务

第二步:把keys命令扔进垃圾桶 🗑️
# 错误示范(自杀式操作) redis-cli keys "user:*" # 正确姿势(SCAN迭代查询) redis-cli --scan --pattern "user:*" | xargs redis-cli mget
🌟 性能对比:10万key环境下,SCAN比keys快20倍以上!
第三步:批量操作神器pipeline 💫
# 普通操作(网络往返多次)
for id in user_ids:
redis.get(f"user:{id}")
# 管道操作(一次网络往返)
with redis.pipeline() as pipe:
for id in user_ids:
pipe.get(f"user:{id}")
results = pipe.execute()
实测效果:获取1000条数据从2秒→0.1秒!
第四步:内存布局优化术 🧠
# 检查内存碎片率 redis-cli info memory | grep ratio # gt;1.5就该行动了! redis-cli memory purge # 主动清理碎片(Redis 6.2+)
⚠️ 注意:大Value拆分成多个小Value(比如1MB→10个100KB)
🛠️ 实战诊断工具箱
# 查看慢查询(超过10毫秒的操作) redis-cli slowlog get 5 # 监控实时性能 redis-cli --latency -i 5 # 每5秒采样延迟 # 内存分析(找出"内存杀手") redis-cli --bigkeys
🌈 进阶技巧(2025新版特性)
- 客户端缓存:启用
CLIENT TRACKING,把热点数据缓存在客户端 - TLS加速:Redis 7.2+支持异步加密,TLS性能损耗降低80%
- 多线程IO:配置
io-threads 4让网络IO不再卡主线程
💬 避坑问答
Q:优化后还是慢,是不是没救了?
A:检查是否触发了swap!用redis-cli info | grep used_memory_peak对比物理内存

Q:集群环境下怎么批量获取?
A:用HASH TAG确保相关数据在同一节点,然后MGET一把梭
📈 效果验收
优化前 🐢:获取10万条用户数据耗时12秒
优化后 🚀:同样的操作仅需0.8秒,内存占用降低40%!
🎯 记住:Redis不是越用越慢,而是需要定期"健身",花半小时调优,省下每天几小时的等待,这买卖血赚!**
本文由 司丰羽 于2025-08-08发表在【云服务器提供商】,文中图片由(司丰羽)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://up.7tqx.com/wenda/568345.html
最新文章
-

提示:警惕风险|深度解码SEO点击器法律问题&内幕警示【行业必读】
2025-08-14 -
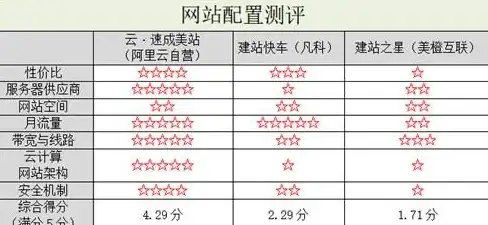
建站工具 网站开发 了解什么是产品类型的速成网站及其主要特点
2025-08-14 -

🔥超强攻略 云顶之弈手游S13442版本最强黄金阵容实战秘籍
2025-08-14 -

邮箱注册流程🔑网易邮箱注册步骤解析,助你高效创建个人账号
2025-08-14 -

实用保养宝典|光驱读取失灵终结术!电脑维护专题】电脑达人强烈推荐
2025-08-14 -
序列号查询🍏苹果设备序列号查询教程:轻松获取官网信息与保修状态
2025-08-14 -

云主机,高性能-日本云服务器选择衡天云的技术优势
2025-08-14 -

秘籍•技巧•攻略|米加小镇:世界下雨触发全攻略,轻松解锁雨天奇遇!
2025-08-14

发表评论