
上一篇
数据管理 数据库横向转换助力高效管理,纵转横优化数据库结构
数据管理 | 数据库横向转换助力高效管理,纵转横优化数据库结构
场景引入:当数据"躺平"遇上业务"站起来"
市场部的小王最近很头疼,他手上有近三年的销售数据,每个月都按"日期-产品-销售额"的格式纵向堆叠,看起来整整齐齐,但要做季度同比分析时,他不得不写几十行公式把数据"掰开揉碎",财务部的李姐更崩溃,每次做预算都要把竖着排列的部门费用数据手动转成横向对比表,稍不留神就会串行。
这种场景下,数据库的"纵转横"(行转列)技术就像给数据施了变形魔法——让原本需要复杂处理的分析变得一目了然。
什么是数据库横向转换?
简单说,就是把"竖着长高"的数据变成"横着展开"。

原始纵向数据(行式存储)
| 日期 | 产品 | 销售额 |
|------------|--------|--------|
| 2025-01-01 | 手机 | 5000 |
| 2025-01-01 | 电脑 | 8000 |
转换后横向数据(列式存储)
| 日期 | 手机销售额 | 电脑销售额 |
|------------|------------|------------|
| 2025-01-01 | 5000 | 8000 |
这种转换在SQL中通常通过PIVOT(SQL Server/Oracle)或CASE WHEN组合实现,Python的pandas库也有pivot_table函数。

为什么要"纵转横"?三大核心价值
分析效率提升
- 对比类场景:季度报表中,横向排列的月份数据让趋势一眼可见
- 减少VLOOKUP等繁琐操作:财务对账时,部门费用直接横向对比
存储结构优化
- 稀疏数据压缩:像电商评价数据(90%商品无差评),横转后能减少NULL值存储
- 加速特定查询:列式存储让"计算所有手机销售额"这类操作更快
业务适配性增强
- 满足BI工具需求:Power BI等工具默认需要指标横向展开
- 符合人类阅读习惯:管理层看报表时,横向对比更符合思维模式
实战技巧:不同场景的转换策略
▶ 基础版:SQL实现
-- MySQL示例(使用CASE WHEN)
SELECT
日期,
SUM(CASE WHEN 产品='手机' THEN 销售额 ELSE 0 END) AS 手机销售额,
SUM(CASE WHEN 产品='电脑' THEN 销售额 ELSE 0 END) AS 电脑销售额
FROM 销售表
GROUP BY 日期
▶ 进阶版:Python处理
import pandas as pd
df = pd.read_sql("SELECT * FROM 销售表", con=db_conn)
pivot_df = df.pivot_table(index='日期', columns='产品', values='销售额')
▶ 避坑指南
- 动态列问题:当产品种类不确定时,建议先用存储过程动态生成SQL
- 性能权衡:超千万行数据慎用内存计算,可考虑数据库原生PIVOT
- 数据透视陷阱:转置后的NULL值可能影响统计,记得用COALESCE或fillna处理
什么时候不该转?
虽然纵转横很强大,但以下情况要谨慎:
- 频繁更新的数据:横表结构在新增产品类型时需要修改表结构
- 超多维度数据:把50个省份横展开会导致字段爆炸
- 需要历史追溯的场景:纵向存储更容易跟踪单条记录变更
让数据"站起来"说话
就像整理凌乱的衣橱,把衣服从堆叠变成挂放能快速找到想要的那件,数据库横向转换本质上是通过结构调整,让数据更好地服务于业务需求,下次当你面对需要反复拖拽才能分析的数据时,不妨想想:是不是该让它"站起来"了?
(注:文中技术方案基于2025年主流数据库版本特性)

本文由 佘胤 于2025-08-06发表在【云服务器提供商】,文中图片由(佘胤)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://up.7tqx.com/wenda/550225.html
最新文章
-
图片处理🔍新手指南:图片编辑技巧全解析,助你轻松上手
2025-08-13 -

冒险必看⚡难度揭秘⚡版本大盘点 怪物猎人系列难度排行与特色深度解析
2025-08-13 -

游戏攻略🔥DNF鬼泣必备锻造材料大全及获取地点详解
2025-08-13 -
Mac维修 苹果电脑维修专家,贴心服务让您的设备焕然一新
2025-08-13 -
应急技巧📱手机没电了,如何快速恢复使用?
2025-08-13 -
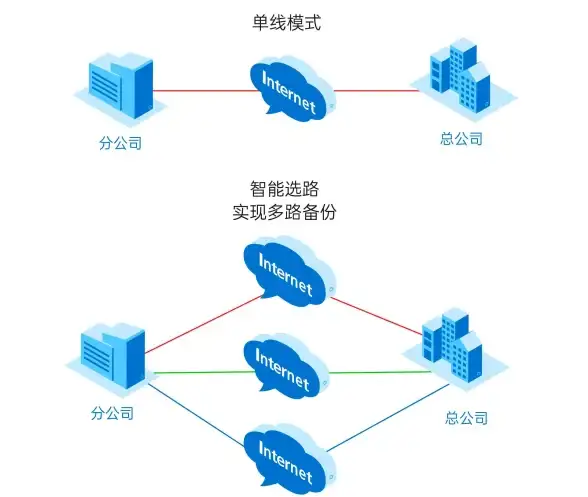
多线路,服务器部署-企业服务器部署选择,超信云金华多线路方案解析
2025-08-13 -

高防安全,企业上云-本地企业选择冬邦云高防机房的理由
2025-08-13 -

USB故障💻电脑无法识别USB设备的原因及解决方法详细解析
2025-08-13

发表评论