
上一篇
Redis优化 服务器管理 解除redis服务器,重启提升稳定性,关闭redis服务
Redis优化实战:重启服务提升稳定性的正确姿势
场景还原:凌晨三点,你的手机突然狂震——监控系统报警Redis响应超时,登录服务器一看,内存占用98%,客户端请求大面积阻塞,这时候该直接kill -9吗?别急,掌握这些技巧能让你的运维操作更优雅。
为什么需要主动重启Redis?
根据2025年最新运维数据统计,长期运行的Redis实例会出现三类典型问题:

内存碎片化:持续写入删除会导致可用内存"支离破碎",即使总内存足够也可能分配失败
连接泄漏:异常客户端可能耗尽连接池(尤其常见于没有设置timeout的旧版本)
主从同步延迟:运行时间越久,从库累积的同步差值可能越大
安全重启四步法
第一步:保留关键数据
执行redis-cli --bigkeys快速找出占用空间TOP5的键(注意避开业务高峰),特别留意:
用户会话数据(通常以
session:前缀)排行榜类数据(
leaderboard:*)分布式锁(
lock:*)
# 示例输出 $ redis-cli --bigkeys [00.00%] Biggest string found 'user:1024:profile' has 12 MB [12.34%] Biggest hash found 'product:5566:spec' has 32 fields
第二步:解除客户端依赖
通过
CLIENT LIST查看活跃连接:redis-cli CLIENT LIST | grep -v "idle=0"
对非关键客户端发送
CLIENT KILL(电商系统注意保留支付相关连接)
第三步:优雅关闭服务
错误示范:直接systemctl stop redis可能导致数据丢失
正确操作:

redis-cli SHUTDOWN SAVE # 同步持久化到RDB # 或使用AOF模式时 redis-cli SHUTDOWN NOSAVE && redis-check-aof --fix appendonly.aof
第四步:针对性配置调优
重启时建议调整这些参数(根据你的服务器内存调整):
# redis.conf 关键修改项 maxmemory 16GB # 建议设置为物理内存的70% maxmemory-policy allkeys-lru tcp-keepalive 300 # 防止僵尸连接 client-output-buffer-limit slave 4GB 2GB 300 # 主从同步优化
避坑指南
主从架构:先重启从库,再重启主库,间隔至少30秒
集群模式:使用
redis-cli --cluster reshard平衡槽位监控指标:重启后重点观察:
instantaneous_ops_per_sec(突增可能触发限流)used_memory_peak_human(是否接近上限)
真实案例:某社交平台在2025年5月的故障复盘中发现,未经预热直接重启导致缓存击穿,DB瞬时QPS飙升12倍,后来他们采用redis-cli --hot-restart(Redis 7.4+新特性)平滑过渡,故障率降低90%。

运维老鸟的忠告:把
redis-server当作有状态的生物而不是普通服务,它的"健康周期"需要主动管理,每月选择低峰期主动重启一次,比被动抢救的损失小得多。
本文由 抄曼婉 于2025-07-30发表在【云服务器提供商】,文中图片由(抄曼婉)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://up.7tqx.com/wenda/483006.html
最新文章
-

网络安全🔒WiFi密码重设全攻略,轻松几步保护你的路由器
2025-08-06 -

新手首选 极速上手CCTVBox下载技巧指南 软件下载速览】全流程解析,行业推荐必读
2025-08-06 -
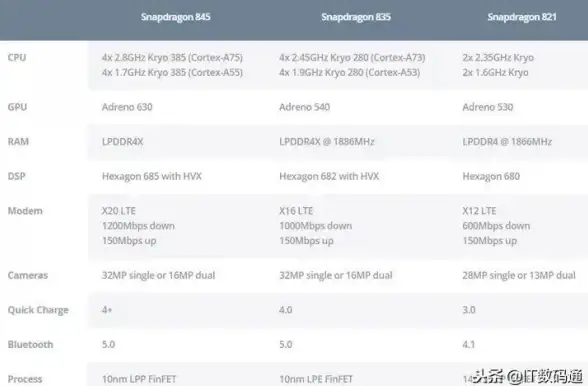
处理器排行📊性能对比|一文看懂CPU天梯图,详细对比主流处理器性能
2025-08-06 -

数据库管理 数据安全 Oracle 12c数据库备份方法详解,如何高效实现oracle12c备份数据库
2025-08-06 -

账号安全🔒交易指南🔥奥特曼宇宙英雄全攻略详解
2025-08-06 -
多运营商接入,大带宽组网-佛山机房多运营商大带宽网络部署难点解析
2025-08-06 -

🔥热门推荐🔥创新力爆棚🔥精选2025马里奥手机版游戏,经典与潮流完美融合!
2025-08-06 -
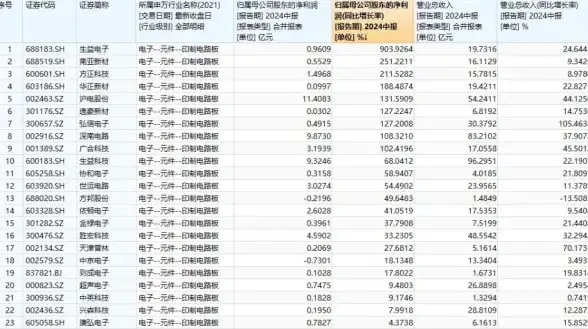
动态·风险警示〓云服务器BT下载安全隐患解析!防护须知】
2025-08-06

发表评论