
上一篇
Redis存储|多键操作 使用Redis高效管理多个键值对,设置和批量处理多组数据
Redis存储 | 多键操作:高效管理多个键值对的实战指南
2025年7月最新动态:Redis Labs最新发布的Redis 8.2版本进一步优化了批量操作性能,特别是在集群环境下的多键处理效率提升了约30%,这使得Redis在大规模数据管理场景中继续保持领先优势。
Redis多键操作基础
Redis作为高性能的键值存储系统,其多键操作能力是开发者必须掌握的核心技能,与单键操作相比,多键操作能显著减少网络往返时间(RTT),提升整体吞吐量。
1 为什么需要多键操作
想象你正在开发一个电商平台,需要同时获取用户的购物车信息、个人资料和最近浏览记录,如果使用单键操作:
cart = redis.get('user:1001:cart')
profile = redis.get('user:1001:profile')
history = redis.get('user:1001:history')
这会产生3次网络请求,而使用多键操作只需1次:
results = redis.mget('user:1001:cart', 'user:1001:profile', 'user:1001:history')
核心多键操作命令详解
1 MSET/MGET:批量设置与获取
MSET命令可以原子性地设置多个键值对:
MSET key1 "value1" key2 "value2" key3 "value3"
MGET则能一次性获取多个键的值:

MGET key1 key2 key3
实战技巧:在Python中使用pipeline进一步提升性能:
pipe = redis.pipeline()
pipe.mset({'item:1': 'A', 'item:2': 'B', 'item:3': 'C'})
pipe.mget('item:1', 'item:2', 'item:3')
result = pipe.execute()
2 DEL:批量删除键
删除多个键只需一次操作:
DEL key1 key2 key3
性能提示:当删除大量键时,考虑使用SCAN+DEL组合避免阻塞:
cursor = '0'
while cursor != 0:
cursor, keys = redis.scan(cursor, match='temp:*', count=1000)
if keys:
redis.delete(*keys)
高级多键操作模式
1 哈希(Hash)类型批量操作
对于对象属性存储,哈希类型更高效:

HMSET user:1001 name "张三" age 28 email "zhang@example.com" HMGET user:1001 name age
2 管道(Pipeline)技术
管道可以将多个命令打包发送,显著提升性能:
with redis.pipeline() as pipe:
for i in range(1000):
pipe.set(f'key:{i}', f'value:{i}')
pipe.execute()
3 Lua脚本原子操作
复杂的多键操作可以通过Lua脚本保证原子性:
-- 原子性地转移两个哈希中的字段
local result = redis.call('HGET', KEYS[1], ARGV[1])
redis.call('HDEL', KEYS[1], ARGV[1])
redis.call('HSET', KEYS[2], ARGV[1], result)
return result
集群环境下的多键操作
在Redis集群中,多键操作要求所有键必须位于同一槽位(slot),可以通过哈希标签确保这一点:
# 这些键会被分配到同一槽位
MSET {user:1001}.name "张三" {user:1001}.age 28 {user:1001}.email "zhang@example.com"
2025年最佳实践:Redis 8.2引入的"集群模式多键优化"允许在某些场景下跨节点执行批量操作,但建议仍尽量保持键在同一节点。

性能优化与陷阱规避
- 合理设置批量大小:建议每批次操作100-1000个键,过大可能导致阻塞
- 注意内存占用:批量获取大量数据可能耗尽客户端内存
- 错误处理:部分失败时,某些命令会继续执行而非回滚
- 监控指标:关注
instantaneous_ops_per_sec和network_in/out_bytes等指标
真实案例:社交网络关系处理
假设处理用户关注关系:
# 批量获取关注状态
user_ids = [1001, 1002, 1003, 1004]
keys = [f'follow:{uid}:{target_uid}' for uid in user_ids]
follow_status = redis.mget(keys)
# 批量更新关注状态
pipe = redis.pipeline()
for uid in user_ids:
pipe.set(f'follow:{uid}:{target_uid}', 1, ex=86400)
pipe.execute()
这种实现比循环单次操作快5-10倍,特别是在跨数据中心场景下差异更明显。
Redis的多键操作就像数据库中的"批发市场",合理使用可以大幅降低系统延迟,提升吞吐量,2025年随着Redis 8.2的优化,即使是超大规模集群也能高效处理批量操作,关键在于找到适合你业务场景的批量大小和操作组合,这需要通过实际测试来确定最佳平衡点。
本文由 计从蓉 于2025-07-29发表在【云服务器提供商】,文中图片由(计从蓉)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://up.7tqx.com/wenda/478873.html
最新文章
-

加密·一键防护|云服务器UPX源码加密新方案揭秘【安全策略精选】
2025-08-04 -

定位服务📱华为手机定位功能全解析:实现精准追踪与隐私安全兼顾
2025-08-04 -

策略🔥部落🔥竞技 魔兽争霸中最强战斗力族群排行榜揭秘
2025-08-04 -
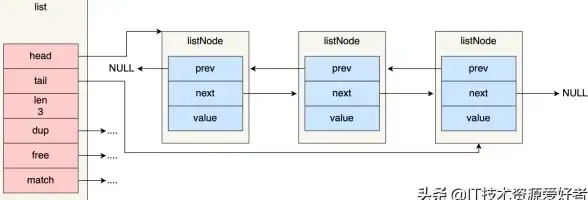
Redis教程 List操作 Redis中List的使用方法及常见用法解析
2025-08-04 -

标签技巧◆游戏攻略◆实用指南 猫和老鼠手游杰瑞知识卡选取全攻略及实战秘技解析
2025-08-04 -

桌面优化🚀图标管理:详解如何把我的电脑图标放到桌面,提升日常使用效率
2025-08-04 -
MySQL 随机数:rand函数生成随机值的多种实现方法
2025-08-04 -
🔥惊悚必玩🔥胆小鬼不可错过的2025恐怖冒险精选惊艳来袭
2025-08-04

发表评论